空间认知模型
TEM(The Tolman-Eichenbaum Machine)
介绍
空间记忆是动物赖以生存的必备认知功能,这一功能的实现和大脑中的海马体密切相关。从1948年起,Tolman就提出动物通过构建"认知地图"来理解环境。近年来,随着对空间记忆研究的深入,人们不禁思考,我们在概念空间、语言空间或关系空间中是否也共享与空间记忆类似或相同的神经机制?
人和其他动物总是能够从稀疏的观察中得出推论,并迅速整合新知识来控制其行为,这些表现与海马体-内嗅皮层系统密不可分。研究表明,空间和关系记忆可能通过共同的机制相关联,但截至目前,尚不清楚这种机制是否存在以及这种机制如何解释多种类型的空间神经元类型。因此,将空间记忆和关系记忆问题重新作为结构抽象和结构泛化的示例以解释海马体的一系列属性显得尤为重要。
TEM将划分为两个因素,一个是图结构,另一个是感官观察。如果知道关系结构,就可以知道在哪里,即使走的是以前没有经历过的路径--这是一种路径整合的形式,但却是针对任意图形的。不过,知道在哪里还不足以成功预测--你还需要记住所看到的东西和看到的地方。这种关系记忆将感官观察与关系结构中的位置结合起来。有了这两个组成部分,感觉预测就变得容易了--路径整合告诉你在哪里,关系记忆告诉你那里有什么。TEM将认知分为感官表征-关系结构两大部分,认为不同的空间/关系中隐藏着一种跨环境保存的结构表征。TEM作为一种关系记忆模型,能够囊括空间和非空间的结构知识。
TEM与海马体
更正式地说,为了促进跨领域的知识归纳,我们把在不同地图之间归纳的抽象位置的变量(g,泛化,网格细胞)与那些基于感觉经验的、特定地图的变量(p,特定,位置细胞)分开。虽然p和g是变量,但它们各自在神经网络中被表示为一群神经元。因此,问题被简化为学习神经网络的权重(W),知道如何(1)表示关系结构中的位置(g)和(2)形成关系记忆(p),存储它们(M),并随后检索它们。尽管网络的权重是学来的,但我们能够在其结构中做出关键的选择。按照Manns和Eichenbaum的观点,海马的表征p是外侧内嗅皮层(lateral entorhinal cortices, LEC)的感觉输入x和内侧内嗅皮层(medial entorhinal cortices, MEC)的抽象位置g之间的结合。
TEM的变量类型可以总结为:\(x \rightarrow p(M) \leftarrow g(W)\),其中①\(x\)表示输入感官特征②\(p\)表示关系记忆,相当于海马体位置细胞③\(M\)表示记忆权重,用Hebbian权重表达④\(g\)表示结构特征,相当于内嗅皮层网格细胞⑤\(W\)表示结构权重,用神经网络参数表达。变量之间的关系如图1所示,TEM计算模型可以直观地表示为图2。
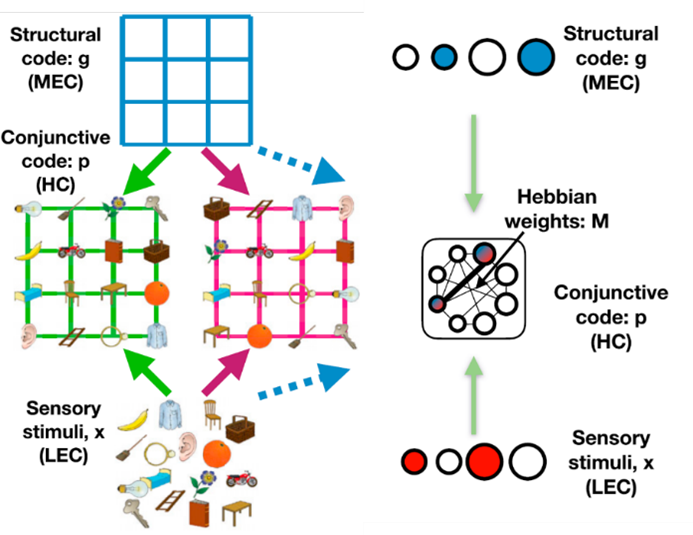
图表 1 变量之间的关系
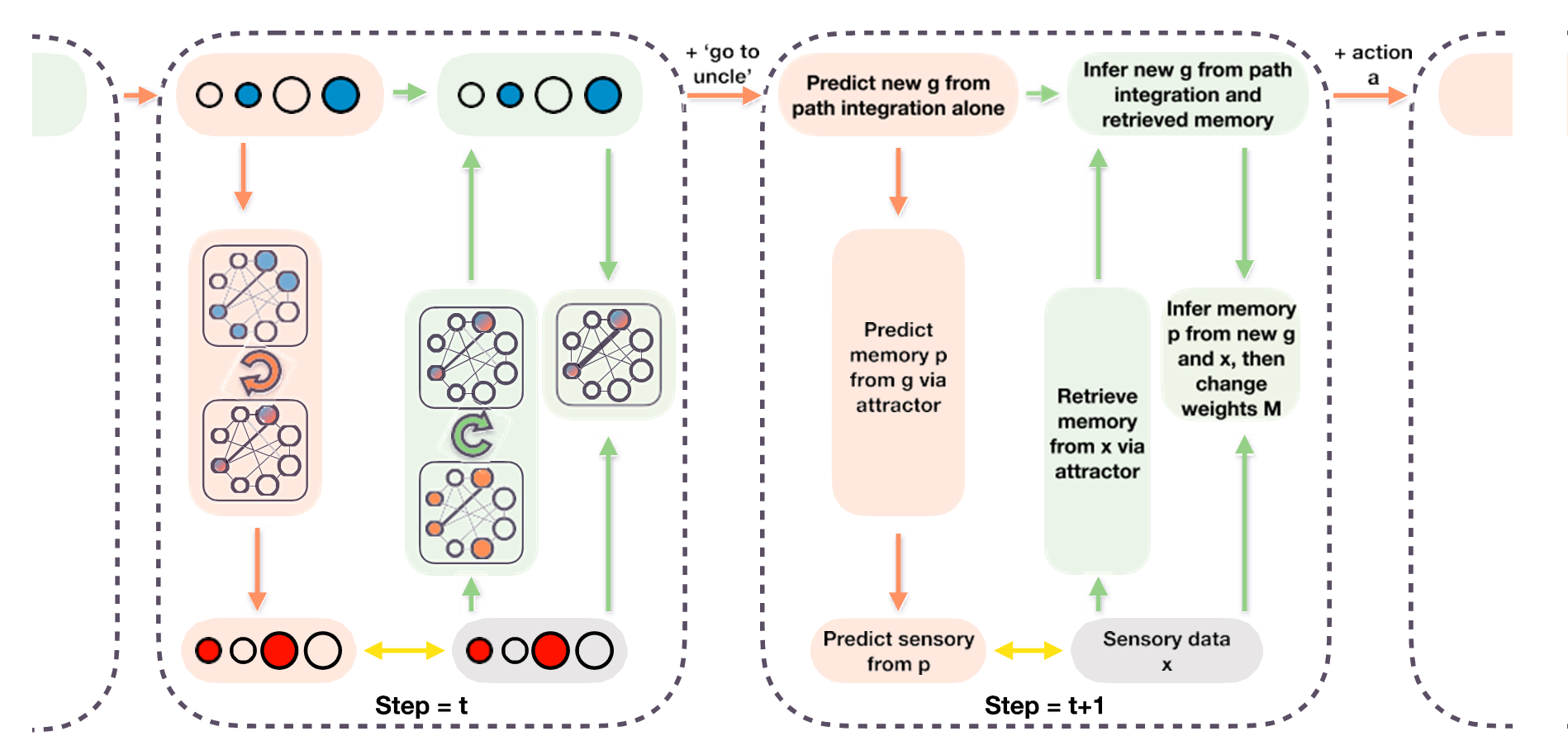
图表 2 在两个时间点的TEM描述,每个时间点的细节描述不同。红色显示预测;绿色显示推理。时间点t显示网络实现,t+1用文字描述每个计算。圆圈描述了神经元(蓝色是g,红色是x,蓝/红是p);阴影框描述了计算步骤;箭头显示可学习的权重;循环箭头描述了循环吸引器。吸引器中神经元之间的黑线描述了Hebbian权重M。黄色箭头显示了训练期间最小化的误差。总的来说,TEM通过潜变量g进行转换,并使用Hebbian权重M存储和检索记忆p。
为了推断出一个新的g表征,TEM从以前的g中执行路径整合,以当前的行动/关系为条件。这可以与位置和网格细胞的递归神经网络模型(RNNs)相关。与这些模型一样,不同的递归权重在改变网络中的活动模式时调解不同行动/关系的影响。与这些模型不同的是,权重是从感觉经验中学习的,允许像地图一样的抽象和路径整合扩展到任意的非空间问题。TEM并非强化学习问题,而是对下一状态\(x^{'}\)的预测问题,因为(1) agent并没有自主做出决策,而是被动输入感官观察\(x\)与动作\(a\)。(2) 认知问题本质上是非马尔可夫性的,下一个观测不止和上一个状态有关,而是和由过去所有观测而形成的记忆\(M^{t - 1}\)有关
当表示具有自重复结构的任务时,分层组织认知图是有效的。为了实现这种层次结构,我们将模型分成多个并行流,每个并行流都如上所述(即,每个流接收x,每个流的g可以通过路径整合进行转换,并且每个流的p是其g和x之间的连接)。这些流仅在形成和检索记忆时被组合。当形成记忆时,海马体中活跃细胞之间的连接M也会更新。当记忆被检索时,这些相同的连接会导致吸引子检索p。分层结构(不同流)之间遵循以下几个原则:(1)不同尺度的流输入特征是相同的,但通过不同的平滑核进行过滤。(2)大尺度模型可以影响小尺度,但反之则不行。(3)尺度越大,所需的神经元数量越少。(4) 记忆矩阵M只能由小尺度流向大尺度,即最大的尺度可以接受小尺度的信息,但小尺度无法接受大尺度的信息
模型训练
TEM可以被看作是一个图的生成模型。不同的环境使用相同的网络权重W用于路径整合,但是使用不同的Hebbian权重M用于记忆网络在每个时间步骤中只看到感官输入x和行动a。它必须构建一个内部的环境表征。g表示是一个RNN:它的递归权重定义了学习的内部结构,每个g表示(在给定的时间步长)对应于地图中的一个位置。当RNN收到一个动作时,它会改变它的表征g。目的是使RNN在回到同一点时有相同的表征(路径整合),所以它可以检索到正确的记忆p。p将一个特定的g表征与一个特定的感觉表征(x)结合起来,并储存在一组权重(M)中供将来调用。这些权重(M)是Hebbian的,因此会随着每次经验的变化而变化,而RNN的权重(W)在网络运行时是固定的,并通过反向传播来调整,以使整体误差最小。
总结
建立一个从计算到细胞活动再到行为的理解,是神经科学的一个核心目标。有望实现这种理解的一个领域是空间导航和海马体。然而,一直不清楚特定细胞反应如何能推广到现实世界的行为中。同样,如何在海马参与广泛的记忆,特别是关系记忆的背景下理解这些空间反应也不清楚。在TEM模型中,通过形式化的关系抽象问题,使用因式分解和连接的代表,有可能解释空间推断作为关系记忆的一个特例。
TEM试图找到包括空间推理的一般原则。值得注意的是,空间推理提供了关系和感觉知识的因素化的一个绝佳例证,也是一个特别强大的概括化的例子,因为关系意义在整个空间中经常重复(O'Keefe and Nadel, 1978)。此外,空间推理在进化中的重要作用可能对导致空间有效计算的表征提供特别的压力。然而,通过更广泛地考虑关系记忆问题,已经表明,能够产生这些空间表征的机制也可以预测更复杂情况下的细胞反应。虽然我们到目前为止考虑的是简单的行为,但我们设想,连同来自强化学习的令人兴奋的见解(Momennejad, 2020; Stachenfeld et al., 2017),这个框架和类似的框架可能有助于将我们的计算理解从开阔地导航扩展到托尔曼关于跨越所有行为领域的系统知识组织的原始想法(Tolman,1948)。
SR(Successive Representation)
背景
Successor Representation最早由MIT的Peter Dayan于1993年提出,以下我们简称SR。考虑到TD算法的核心是估计从当前时刻开始到未来的累积奖励值(value function),Dayan认为这个值和后继状态的相似度关系密切。如果有一个很好的表征(representation)能够描述当前状态到未来某个状态的转移特性,则value function就可以分解为两个部分,一部分是这个表征,另一部分描述奖励函数。于是他提出了SR的方法,结合TD learning的优势和基于模型算法的灵活性,使得该算法被称为除了model-based和model-free的第三类强化学习算法。
SR的定义以及其与强化学习之间的关系
传统的强化学习,通过一个特定的reward函数来指定一个具体的任务,即\(r(s,a,s^{'})\)这里,作者假设reward函数可以表示成:
\[r\left( s,a,s^{'} \right) = \phi\left( s,a,s^{'} \right)^{T}\omega\]
其中\(\phi\left( s,a,s^{'} \right) \in \mathcal{R}^{d}\)是关于\((s,a,s')\)的特征,t时刻下该值为\(\phi\left( s_{t},a_{t},s_{t + 1} \right) = \phi_{t}\),\(\omega\)是权重。策略函数\(\pi\)的Q函数可以表示为:
\[Q^{\pi}(s,a) = E^{\pi}\left\lbrack \sum_{i = t}^{\infty}{\gamma^{i - t}\phi_{i + 1}|S_{t} = s,A_{t} = a} \right\rbrack^{T}\omega = \psi^{\pi}(s,a)^{T}\omega\]
其中\(\psi^{\pi}(s,a)^{T}\)是策略\(\pi\)下状态-动作二元组(s, a)的successor features。因此,Q函数的学习,包含了对\(\psi^{\pi}\)和\(\omega\)的学习。Q函数不仅可以表示为后继连续状态序列的特征加权,还可以表示为当前特征与未来某一时刻的后继状态之和的形式:
\[{Q^{\pi}(s,a) = \sum_{s^{'} \in S}^{}{M\left( s,s^{'},a \right)R\left( s^{'} \right)} }{= E\lbrack\sum_{t = 0}^{\infty}{\gamma^{t}1\left\lbrack s_{t} = s^{'} \right\rbrack|s_{0} = s,\ a_{0} = a}\rbrack R(s')}\]
其中\(1\lbrack \cdot \rbrack = 1\)表示括号里为真,0表示非真,若想取得Q函数的精确值,需要对状态空间的每一个状态\(s'\)进行遍历求解,这大为消耗计算资源。因此,可以利用非线性函数拟合器来逼近这里的Q函数。
首先,将每个状态用一个D维的特征向量\(\phi_{s}\)来表示,并用一个参数化的神经网络将状态映射到特征空间中,即\(f_{\theta}\mathcal{:S \rightarrow}\mathcal{R}^{D}\)。\(\omega\)的学习,和reward有关,如果有了\(\phi\),则\(\omega\)的学习就是普通的监督式学习,针对每个successor features的学习,需要利用Q函数的贝尔曼方程形式:
\[\psi^{\pi} = \phi_{t + 1} + \gamma E^{\pi}\lbrack\psi^{\pi}(S_{t + 1},\pi(S_{t + 1}))|S_{t} = s,A_{t} = a\rbrack\]
以上就是基于SR做强化学习的基本模式,这种方式使得Q函数的求解转化为①SR的求解和②权重\(\omega\)的求解。可以发现,前者的学习由于具有Bellman方程形式,因此一般的强化学习算法都适用于求解该问题;对于后者,则普通的监督学习算法就可以拟合了。SR作为环境状态的一种表征,对不同的任务具有一般性,因此这种算法求出来的模型比较稳定和灵活。不同的\(\omega\)可以代表不同的任务,所以也具有一定的可迁移性。
SR的优势与缺点
SR算法最值得借鉴的地方就是将reward函数分解成两部分,一部分是通用的状态转移数据的特征;一部分是描述任务的权重,和任务有关。这样做,就把一族任务用特征函数\(\phi(s,a,s')\)来表示了,而任务族内部各任务,则由权重向量\(\omega\)来表示。
尽管基于SR的强化学习具有一定的迁移性,但是毕竟状态的转移是和策略息息相关的。一旦策略发生变化,则学习出来的SR或者SFs仍然需要继续学习才能保持其准确性。也就是说,对于迁移强化学习来说,它仍具有一定的不足。例如,状态函数该如何设计、如何学习,哪些任务不在可迁移状态集\(\mathcal{M}\)以内,仍需更多讨论。
SR与认知地图
学习预测长期回报是许多动物生存的基础。一些物种在获得主要奖赏之前可能要经过几天、几周甚至几个月的时间,在此期间必须忍受厌恶的状态。有证据表明,大脑已经进化出多种解决方案来解决这一强化学习(RL)问题。一种解决方案是学习环境的模型或认知地图,然后通过对未来状态的模拟来产生长期的奖励预测。然而,这种解决方案是计算密集型的,特别是在现实世界的环境中,未来可能性的空间几乎是无限的。另一种无模型的解决方案是通过试验和错误学习一个价值函数,将状态映射到长期奖励预测。然而,动态环境对这种方法来说可能是有问题的,因为奖励分布的变化需要完全重新学习价值函数。
当动物处于空间中一个特定的位置时,位置细胞会有选择性地做出反应。关于位置细胞的一个经典且仍有影响力的观点是,它们共同提供了一个明确的空间地图。然后,这个地图可以作为基于模型或无模型的RL系统的输入,用于计算动物当前状态的价值。相反,预测图理论认为位置细胞是对未来状态的预测进行编码,然后可以与奖励预测相结合来计算价值。这一理论可以解释为什么位置细胞的激活会受到障碍物、环境拓扑结构和旅行方向等变量的调节。它还可以解释非空间任务中海马的编码。在海马之外,我们认为,在空间上周期性激活的位于内嗅皮层网格细胞,对预测地图的低维分解进行编码,对稳定地图和发现子目标很有用。
Stachenfeld et al. (2017)利用SR模型来对预测图理论进行建模。SR模型的主要观点是,位置细胞并不对位置本身进行编码,而是对当前状态下的未来状态进行预测性表征。因此,两个物理上相邻的状态预测不同的未来状态将有不同的表征,而两个预测相似的未来状态将有相似的表征。因此,当未来状态的奖励被引入、移动或改变时,SR允许快速计算新的价值函数。该文最主要的理论假设是:SR模型是由海马体进行编码的。这一假设是基于海马体在代表空间和背景方面的核心作用,以及它对顺序决策的贡献。虽然SR可以应用于任意的状态空间,但我们在此关注的是空间领域,在这个领域中,状态是指位置。传统上,海马中的位置细胞被看作是对动物当前位置的编码。与此相反,预测图理论认为这些细胞是对动物未来位置的编码。至关重要的是,动物的未来位置取决于它的策略,它受到各种因素的制约,如环境拓扑结构和奖励的位置。
总结
SR作为一种状态表征方式,结合了model-based和model-free两类算法的优势,使得基于SR的算法在模型灵活性和计算效率上有一个较好的折中。SR的这一特点被应用在了迁移强化学习中,但是仍然具有一定的限制。对于迁移强化学习来说,最好能从不同任务、不同环境中找到一个可迁移的特征表达。但是Successor Representation却不具备理想的特征可迁移性,因为它依赖于一个特定的策略。一旦学到了某个任务最优策略的SR,则不太容易直接将它迁移到另一个不同任务的最优策略上。
CGCS(Clone-Structured Congnitive Graph)
介绍
通过心理时间旅行评估未来的能力,是智力的一个标志。要做到这一点,agent需要从周围环境的感觉信息流中学习认知地图。根据上下文信息,相同的事件可能有不同的解释,不同的事件可能意味着相同的东西。因此,关于认知地图的计算理论应该 (1)提出上下文和位置特定的表征如何从不一致的感觉或认知事件中产生的机制,以及(2)描述表征结构如何实现巩固、知识转移以及灵活和分层的规划。一个agent经常会遇到外部情况,这些情况看起来瞬间相似,但根据上下文需要不同的行动策略,在这些情况下,感官观察应该被情境化为不同的状态;在其他情况下,看起来不一样的感官观察可能需要合并到同一个状态中,因为这些背景都会导致相同的结果。为了从连续的观察中形成一个灵活的世界模型,代理人需要有一个表征结构和一个学习算法,允许在适当的时候对上下文进行分割与合并。此外,表征结构应该是允许动态规划和处理不确定性的。
因此,该文提出了一种特殊的高阶图------克隆构成的认知图(CSCG),它将观察结果映射到不同的克隆单元上,作为一种表征结构来解决上述问题。利用高阶序列学习和概率推理的原则,CSCG可以解释各种认知图的现象,如从混叠的感觉流中发现空间关系,在不相干的经验事件之间进行传递性推理,可转移的结构知识,以及在新环境中寻找捷径。CSCG还可以学习分离共享观察的多个环境,然后根据上下文的相似性来检索它们。值得注意的是,克隆结构学习和推理的动力学对大鼠从一个环境移动到另一个环境时观察到的不同活动重映射现象给出了一致的解释。通过将异样的观察结果提升到一个隐藏的空间,CSCG揭示了潜在的模块化,并且可用于分层抽象和规划。
方法
CSCG的核心思想是动态马尔科夫编码,这是一种通过分割或克隆观察到的状态来表示高阶序列的方法。克隆机制允许稀疏地表示高阶依赖关系,通过克隆,相同的自下而上的感觉输入由多种状态表示,这使得大量的高阶和随机序列的有效存储没有破坏性的干扰。然而,学习动态马尔科夫编码是具有挑战性的,因为克隆依赖于一种贪婪的启发式方法,导致严重的次优化------与零阶或一阶片段穿插的序列将导致克隆状态的不可控增长。虽然将克隆思想纳入了生物学习规则,但由于缺乏概率模型和连贯的全局损失函数,阻碍了其发现高阶序列的能力,也无法有效地代表上下文。一个有效的学习方法应该拆分克隆来发现高阶状态,并在有助于泛化的情况下灵活地将它们合并。
在克隆HMM中,每个状态的最大克隆数是预先分配的,这会造成容量瓶颈。使用期望最大化(EM)算法进行学习来找出如何适当地使用这种能力来拆分或合并不同的上下文,以有效地使用克隆来表示不同的上下文。HMM和克隆的HMM都假设观察到的数据是从遵循马尔可夫性质的隐藏过程生成的。也就是说,给定当前状态和所有过去状态,未来状态的条件概率分布仅取决于当前状态,而不取决于任何过去状态。
不同于HMM,在克隆HMM中,许多隐藏状态确定地映射到相同的观察(图3b)。映射到给定观察的一组隐藏状态被称为该观察的克隆。我们使用\(C(j)\)来表示观察\(j\)的克隆集。克隆HMM中序列的概率是通过对隐藏状态进行边缘概率加和来获得的。此外,由于每个隐藏状态斗鱼单个观测相关联,因此基于EM的学习在克隆HMM中更有效。
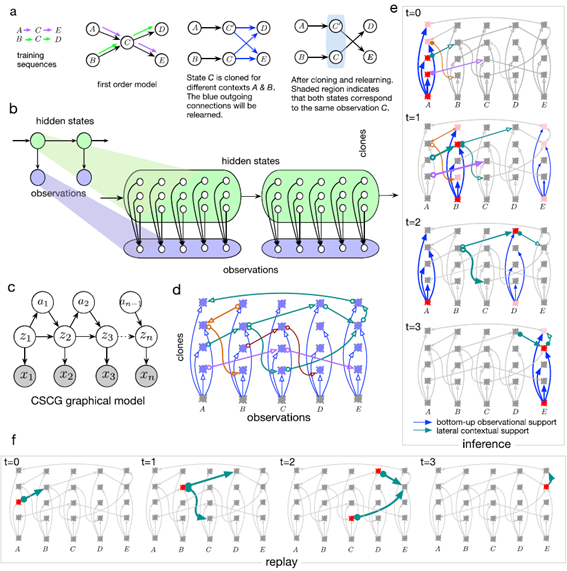
图表 3 (b) 动态马尔可夫编码的克隆结构可以用具有结构化发射矩阵的HMM表示,即克隆HMM。(c)CSCG的概率图模型,通过加入动作来扩展(b)中的克隆HMM。(d)克隆HMM的神经实现。箭头是轴突,侧面连接实现克隆HMM过渡矩阵。不同的序列有不同的颜色,例如A→C→E为紫色。列中的神经元是彼此的克隆,它们从相同的观察中接收自下而上的输入(蓝色箭头)。(e)克隆HMM神经回路中的推断动力学。神经激活强度用红色阴影表示。向前传播的激活是具有上下文(横向)和观察(自下而上)支持的激活。
像HMM一样,克隆HMM可以很容易地被实例化为一个神经元回路(图3d)。每个克隆对应于一个神经元,这些神经元之间的 "横向"连接形成了克隆HMM过渡矩阵。过渡矩阵也可以被视为一个有向图,神经元构成图的节点,轴突分支构成有向边。互相克隆的一组神经元从观察中得到相同的"自下而上"的输入。克隆神经元的输出是其横向输入的加权和,乘以自下而上的输入,对应于HMM推理中的前传信息。
CSCG在克隆HMM的基础上进行了扩展,以包括agent的行动。Agent的可观测序列为状态-动作对\(\{\left( x_{1},a_{1} \right),\left( x_{2},a_{2} \right),\ldots,(x_{n},a_{n})\}\)。在CSCG中,行动是当前隐藏状态的一个函数,而未来的隐藏状态是当前隐藏状态和所采取的行动的一个函数。这个CSCG的图模型在图3c中描述。在数学上,联合观察行动密度为:
\[P\left( x_{1},\ldots,x_{N},a_{1},\ldots,a_{N - 1} \right) = \sum_{z_{1} \in C(x_{1})}^{}{\ldots\sum_{z_{n} \in C(x_{n})}^{}{P(z_{1})\prod_{n = 1}^{N - 1}{P(z_{n + 1},a_{n}|z_{n})}}}\]
CSCG允许agent学习哪些行动在给定的状态下是可行的,相比之下,TEM只预测行动的未来观察。总的来说,CSCG首先通过扩展HMM模型的隐状态,利用多个隐状态对应于一个实际观测,解决了观测---认知混杂的问题;之后将隐状态与观测结合,形成了最终的CSCG模型。
实验与结果
从混叠序列观测中出现空间地图。
从没有唯一识别空间位置的纯顺序随机行走观察中,CSCG可以学习基本的空间地图,这种能力与人和动物相似。即使大多数观察结果是混叠的,CSCG也可以学习空间拓扑结构。
传递推理
不连贯的经验可以拼接成一个连贯的整体。传递性推断,即推断没有同时经历的项目或事件之间的关系的能力,归因于认知地图。例如,通过了解A>B和B>C来实现A>C,或者根据地标及其在不同旅程中的相对位置推断出一种新的城市导航方式。
可复用的图形结构来探索类似的环境
CSCG在一个房间里学到的通用空间结构可以作为一种模式,用于探索、规划和寻找新房间的捷径,这很像基于海马体的导航能力。即使对一个新的房间只有部分的了解,agent也可以通过重用CSCG在熟悉的房间里的过渡图,来替代评估到达目的地所要采取的行动的数量和类型。
路径和时间顺序的表示
CSCG学习路径并表示时间顺序,例如,当观察结果对应于动物重复行进的典型路线时。神经生理学实验表明,海马中出现了"分裂细胞"。这些细胞代表了通往目标的路径,而不是物理位置,当老鼠重复穿过相同的顺序路线而不是随机行走时,这些细胞就会出现。对于一阶模型,当到达共享路段时,将丢失关于先前路段的所有上下文,并且模型将对未来路径做出错误预测。另一方面,CSCG能够捕捉路径的历史,从而正确地建模路线及其不同的开始状态。
需要注意的是,CSCG学习灵活的高阶序列的能力与模态无关。特别是,输入可以对空间观察、气味、字符序列或任何其他现象的观察作出响应。CSCG将学习生成过程基础图形的近似值,与Tolman所设想的认知地图的角色密切对应。
学习多种地图并解释重映射
重映射是海马位置细胞活动因物理环境的变化而重组的现象。重新映射可以是全局的,也可以是部分的,取决于海马如何分离、储存和检索可能相似或不相似的多种环境的地图。与海马体类似,一个单一的CSCG可以为不同的环境分离地图,这些环境有相似的瞬时观察,在记忆中同时表示这些地图,然后利用上下文的相似性来检索适当的地图来驱动行为。
社群检测和分层规划
人类是分层次地表示计划的。间接评估模拟通往目标的路径,而分层计算通过减少搜索空间使这些模拟具有可操作性。为了实现分层规划,学习机制应该能够从顺序观察的数据中恢复基本的分层结构。
通过学习克隆的过渡图,CSCG将观察结果提升到隐藏的空间,使得发现观察中可能不明显的图的模块化。然后,社群检测算法可以对图进行分割,形成对规划和推理有用的层次抽象。像CSCG中的规划和推理一样,社群检测也可以用消息传递算法来实现。在类似的环境下,信息传递算法已知有生物学上合理的神经元实现。
SMP(Spatial Memory Pipeline)
介绍
SMP,将传入的知觉刺激与来自记忆的预测进行比较。考虑到这一点,我们开发了一个由带有外部记忆的模块化循环神经网络(RNN)组成的模型---Spatial Memory Pipeline。在每一个时间步,进入管道的视觉输入用卷积神经网络进行压缩,并与存储在记忆存储槽中的先前嵌入进行比较,最佳匹配被最强烈地反应。管道的其余部分被训练来预测哪个视觉记忆槽将被重新激活(图4A)。预测完全是在自我运动信息的基础上产生的,这些信息以角速度和线速度的形式不同地提供给RNN模块,此外还有来自先前步骤的视觉校正。从详细的视觉特征到管道的后期部分没有直接的途径--视觉信息只通过激活记忆存储中的槽来传达(图4B)。因此,空间记忆管道形成了一个预测代码,预测未来哪个视觉槽将被激活,完全基于自我运动。
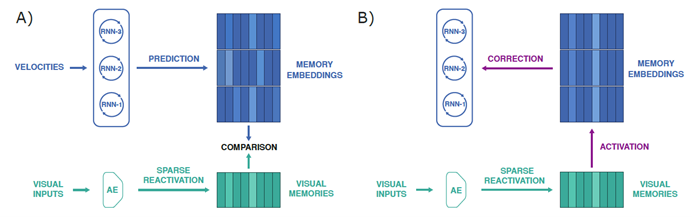
图表 4 A)在预测步骤中,一组RNN通过整合自我中心速度来预测过去视觉记忆的重新激活------AE表示自动编码器。B)在校正步骤中,重新激活的视觉记忆校正RNN的状态以减少累积误差。
方法
SMP由两个子模块组成,学习独立进行。第一级是降低视觉输入维度的视觉特征提取网络。在视觉特征提取之后,通过整合以自我为中心的速度,在时间上存在一定程度的整合,从而对agent位置的估计进行编码。我们将此集成级别称为内存映射。它由一个基于快速结合槽的联想记忆和一组循环神经网络组成,后者接收自我中心速度信号作为输入,并扮演人工大脑皮层的角色。
视觉特征提取:SMP的第一级采用卷积自编码器(autoencoder, AE)网络(图5 A),该网络将原始视觉输入\(y_{raw}\)转化为低维视觉编码向量\(y_{enc}\),该向量总结了输入的结构。所有的编码与解码组件以最小化重建误差\(\left| y^{(raw)} - {\widehat{y}}^{(raw)} \right|^{2}\)来进行优化。对于我们的大多数实验,仅使用编码器网络将原始图像转换为视觉编码,作为下游存储器映射的输入。然而,在重放实验中,解码器网络也被用于从记忆的编码中重建图像。
记忆映射:该模块由两个组件组成:一组递归神经网络\(R\),其整合了自我中心速度;以及一个基于记忆槽的联想存储器\(M\),其将上游输入\(y\)绑定到RNN的状态值。在每一步时间\(t\)上,上游输入\(y_{t}\)重新激活作于相似内容的插槽(图5 B),该过程可以被形式化为内存槽上的分类分布形式化。
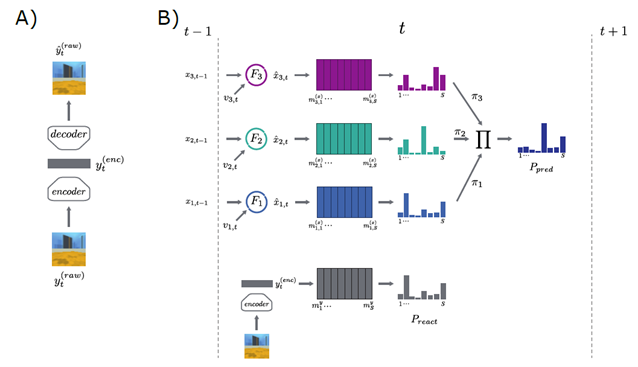
图表 5 A) 视觉特征提取模块,利用自编码器将输入影像特征压缩为特征向量 B) 基于内存插槽的关联记忆模块,由上一刻的输入和此刻的视觉输入、速度输入等进行记忆激活
总结与对比
尽管在物理空间中很容易推测出好的状态空间,但现实中的非空间问题很难转化为认知地图的形式。一种源自强化学习的方法是将空间学习作为理解图上的关系。在空间中,图的节点定义了物理位置,因此,如果两个位置直接相连,节点之间就有边。重要的是,图也可以将非空间问题形式化。例如:家庭树、社会网络和分子中的原子,都是由实体之间的关系组成的,可以用图来表示。因此,图中的节点代表非空间位置。图定义了状态空间,因此能够实现基于价值的强化学习。它们还可以进行规划:每个状态都可以由一个向量元素\(v\)来定义,状态位于某一节点,则除该节点的值为1之外,所有元素都设置为0;然后将\(v\)乘以\(T\)(\(T\)是转换矩阵,其中\(T_{ij}\)是从状态\(i\)到\(j\)的转换概率),在一步之后得到未来状态的分布。同样,再次乘以\(T\)(\(vT^{2}\)),得到两步之后的分布。重复这个过程,就可以得到节点之间的最短路径。目前已经有基于海马体的图模型(successor representations, SR),并且它们对空间的表征类似于位置和网格细胞。
为了实现灵活行为,我们可以将多种原则(模型)结合起来,通过结合学习潜在状态的模型,以及路径整合的模型,我们就可以建立一个更强大的系统。不仅可以从感官观察中学习任意的潜在状态(如CSCG),但又能额外地泛化这些表征(如路径整合模型)并任意地组合它们。此外,为了使抽象表征在不同的感觉环境中被重复使用(泛化),相同的抽象位置必须与不同的感觉观察 "相联系"。
目前,基于海马的泛化模型有TEM和SMP。该类模型的任务是尽可能快地预测新的、但结构相似的环境中的感官观察(例如,多个不同的家庭或二维世界)。两个模型都由两个关键部分组成。(1) 一个抽象的路径整合模块,可在不同的环境中重复使用;(2) 一个关系记忆模块,该模型像地址簿一样,将抽象的位置表征与感觉表征联系起来。这些联系在不同的世界中会发生变化,允许相同的抽象概念适用于多个世界。
尽管TEM和SMP在概念上是相同的模型,但它们有不同的实现方式。两个关键的问题是:(1)TEM提供了非自我中心的的行动和物体表征,但SMP必须从以自我为中心的输入和像素中学习;(2)SMP用机器学习中的记忆网络来实现记忆,而TEM使用更符合生物现实的Hebbian learning和Hopfield networks。这种生物约束意味着抽象世界和感觉世界之间的联系必须发生在一个神经元单元中;也就是说,同一个海马神经元必须同时知道抽象位置和感觉预测。这种联合表征(conjunction representation)通常在海马神经元中被观察到。在TEM中,这种联系表征通过海马重映射(remapping)从而实现泛化------相同的皮层表征(LEC和MEC)在不同的环境中被重复使用,而联合形成的海马神经元则不同,从而使得结构可以泛化在不同的场景。TEM和SMP都是深度神经网络,它们学习可泛化的结构知识,并在此过程中可以重现海马认知图谱的一系列已知表征。由于SMP是以自我为中心的输入,它产生的细胞参与了从自我为中心到分配中心的坐标转换。此外,TEM在空间和非空间任务中学习组合式的内嗅皮层表征,并能解决主要依赖于海马的经典关系记忆任务,如传递性推理(transitive inference.)。
参考文献
Whittington, J. C., Muller, T. H., Mark, S., Chen, G., Barry, C., Burgess, N., & Behrens, T. E. (2020). The Tolman-Eichenbaum machine: Unifying space and relational memory through generalization in the hippocampal formation. Cell, 183(5), 1249--1263.
Dayan, P. (1993). Improving generalization for temporal difference learning: The successor representation. Neural computation, 5(4), 613-624.
Stachenfeld, K. L., Botvinick, M. M., & Gershman, S. J. (2017). The hippocampus as a predictive map. Nature neuroscience, 20(11), 1643-1653.
George, D., Rikhye, R. V., Gothoskar, N., Guntupalli, J. S., Dedieu, A., & Lázaro-Gredilla, M. (2021). Clone-structured graph representations enable flexible learning and vicarious evaluation of cognitive maps. Nature communications, 12(1), 2392.